TL;DR: Cursor leads on setup speed, Docker/Render deployment, and code quality, while Claude Code is best for rapid prototypes and a productive terminal UX. Gemini CLI wins for large-context refactors, and Codex’s model is powerful but hampered by UX issues. Jump to the results.
“Extreme skeptic” was an accurate way to describe my thoughts on AI agents, generated “vibe coded” apps, and the eventual demise of my long-time profession as a software engineer.
Until February 2025, I limited my AI exposure to the single-line auto-complete feature of GitHub Copilot, which saved me a bit of typing. However, its context collection was so poor that I really just treated it as a toy, not a productivity-enhancing tool.
I have more recently started exploring the idea of targeted agent use in my production codebases, but I still approached it with cautious skepticism, as I had spent more time at this point cleaning up AI produced messes in prod that I had written AI assisted code myself. However, in the cutthroat tech world of “innovate or die,” I thought it was high time to test these tools out for real, and in a deliberate engineering manner.
AI coding tools in 2025
As of mid-2025, there are more code agent AI tools than I can count; however, I selected the following four. These should give a good mix of models and UX differences for us to test.
- Claude Code: A solid CLI offering from Anthropic; it supports code diff’ing in IDEs, MCP tools, and Anthropic’s respected LLMs.
- Cursor (using Claude Sonnet 4 for all tests): A fully integrated IDE experience, this will be the only non-CLI tool I’ll test. It offers a wide range of model choices, which will contribute to test variability, but we’ll stick with just Sonnet 4 to hopefully maintain consistency. A point of interest: Cursor utilizes a RAG-like(Retrieval-Augmented Generation) system on the local filesystem to gather more context on the codebase, potentially giving it an advantage.
- Gemini CLI: Google’s offering in the code agent space offers the solid Pro 2.5 model, which has the highest context window of all the models by far (1M tokens).
- OpenAI Codex: OpenAI’s models are renowned for accuracy and creativity, but let's see how their code tool works. They also have a cloud-based IDE in the works, but at this time, we’ll just be testing the production-ready CLI.
Evaluating vibe coding vs. production
To cover all use cases that an engineer would need in a production environment, I decided on two sets of tests:
- A contrived control app, 100% “vibe coded” from a blank repo. This would give us an idea of the ability of each tool to generate useful boilerplate and possibly fully working MVPs. As of this test, I’ve never truly “vibe coded”, so this will be very interesting.
- A battery of tests against two huge code repos that were created before the age of AI. The first is a large Go API monorepo, and the second is an Astro.js website (my website, to be exact!) that requires several new templates and CSS updates. These tests should challenge the agents' abilities, as they contain custom implementations and non-standard code problems that will assess the agent’s capacity to gather and utilize local context.
First impressions on setup
I’m of the firm belief that tools should be quick to install and set up; a download and install, maybe an account login, and you should be good to go. In a world of automation and shell scripts, why not?
Unfortunately, with some of these tools, that was not the case…
Claude Code
Claude was super easy to set up! Just an npm install, a login command (and prompt that you need a paid account), and we’re off to the races! It even recognized that I was using JetBrains IDEs and offered to install a code diffing visualization plugin for me.
Cursor
This was also an easy setup, just install and run; I didn’t even have to create a paid account to try it out (though totally necessary if you plan on doing any real work).
Gemini CLI
This is where things got interesting. The CLI install itself is easy, but I ran into some complexity regarding my Google Workspace account; because I was in a Workspace org, I had to sign up for a usage-based plan, enable the Gemini API in my GCP account, and create an API key in Google AI Studio before I could test the tool.
The good news is that the free usage limit was high enough that I didn’t have to spend any money on credits.
OpenAI Codex
Codex’s setup was wild….
The CLI installed easily enough, just a standard NPM install. I also used the login command to log in to my OpenAI account. I had read that it required a paid account, so I went ahead and loaded some credits.
stream error: stream disconnected before completion:... Not the most helpful error message in the world. After some research on GitHub, I discovered that my account needed to be verified, which involved uploading a government-issued ID and taking facial recognition photos.
Easy, after all that, it's running fine!
Test #1: Using AI agents for vibe coding
For the baseline test, I prompted each tool with a single prompt to create a simple full-stack app in Next.js. The app would require a UI, a simple database with a table, and a Docker-based deployment. Bonus: I patched in Render’s MCP tool and an API key, and we should be able to deploy straight to the web with one (or maybe a few) prompts.
Please build a simple url shortener app. Please build it in nextjs with a minimalist style using the mui component library. The app should have a single input field that takes in a URL from the user and returns a shortened/encoded url. For the backend, provide a postgres connection for connecting to a database and storing the shortened urls. The app should be deployable via a dockerfile.
After the initial prompt above, I’ll only feed any error messages back to the agent, without providing hints or context on what it should do.
After the app was running locally, I finally asked the agent to deploy to Render using their new MCP server.
Cursor (9/10)
Number of follow-up error prompts: 3

Cursor destroyed the competition with the cleanest and most full-featured app. It exhibited a good base styling, complete error message handling, and excellent UX.
It was the only agent to successfully create a Docker Compose file with a database, as well as a SQL migration script for the necessary table.
There were a few issues that it had to work on: the /public directory that Next.js uses for static assets didn’t make it into the Docker build. It also attempted to connect to the database using SSL, which wasn’t enabled.
Objectively speaking, Cursor produced the best app without intervention, and with Opus, it probably would be even better!
Claude Code (7/10)
Number of follow-up error prompts: 4
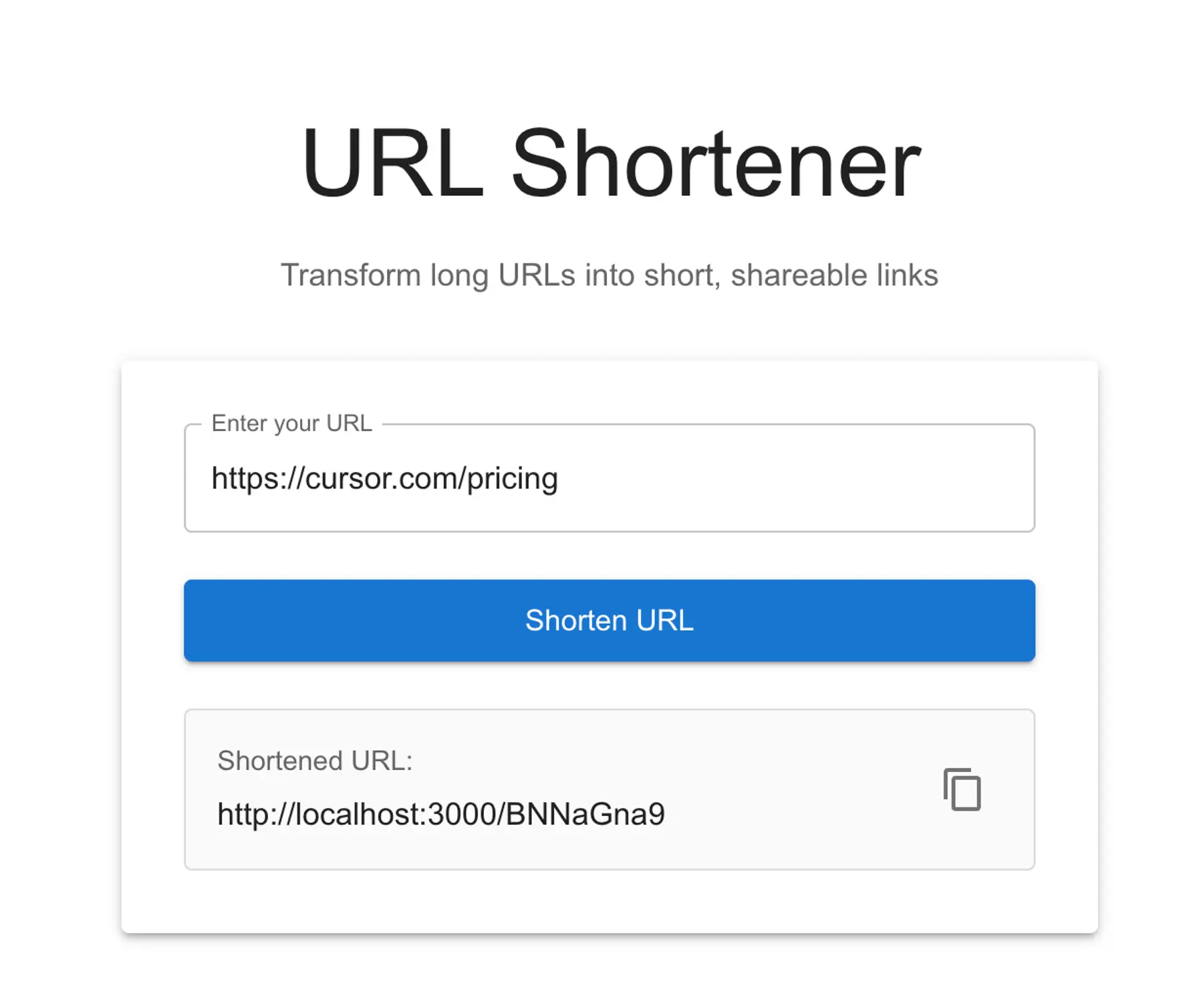
Claude put up an admirable fight, with a simple but well-designed app. It struggled with a few Next.js-specific issues, including theme creation, and the pesky /public folder omission, requiring a few prompts to resolve.
Speaking of Docker builds, it didn't think to create a compose file, which wasn’t explicitly asked for on purpose, to see what they do.
Once deployed, the functionality worked on the first try!
OpenAI Codex (5/10)
Number of follow-up error prompts: 4

Codex performed admirably, but the UX felt somewhat primitive compared to the other tools tested so far; the information displayed on the CLI wasn’t as informative and when it ran into a non-show-stopping problem, it wasn’t as good as informing the user what had happened.
The UI styling was serviceable and included good error message UX, perfectly fine for a boilerplate starting point.
It did however fail in some of the same places as Claude code: it missed the Docker Compose and SQL migration scripts, and had trouble with some of the framework specifics of Next.js.
Overall, it was pretty quick to get a usable app up and running.
Gemini CLI (3/10)
Number of follow-up error prompts: 7
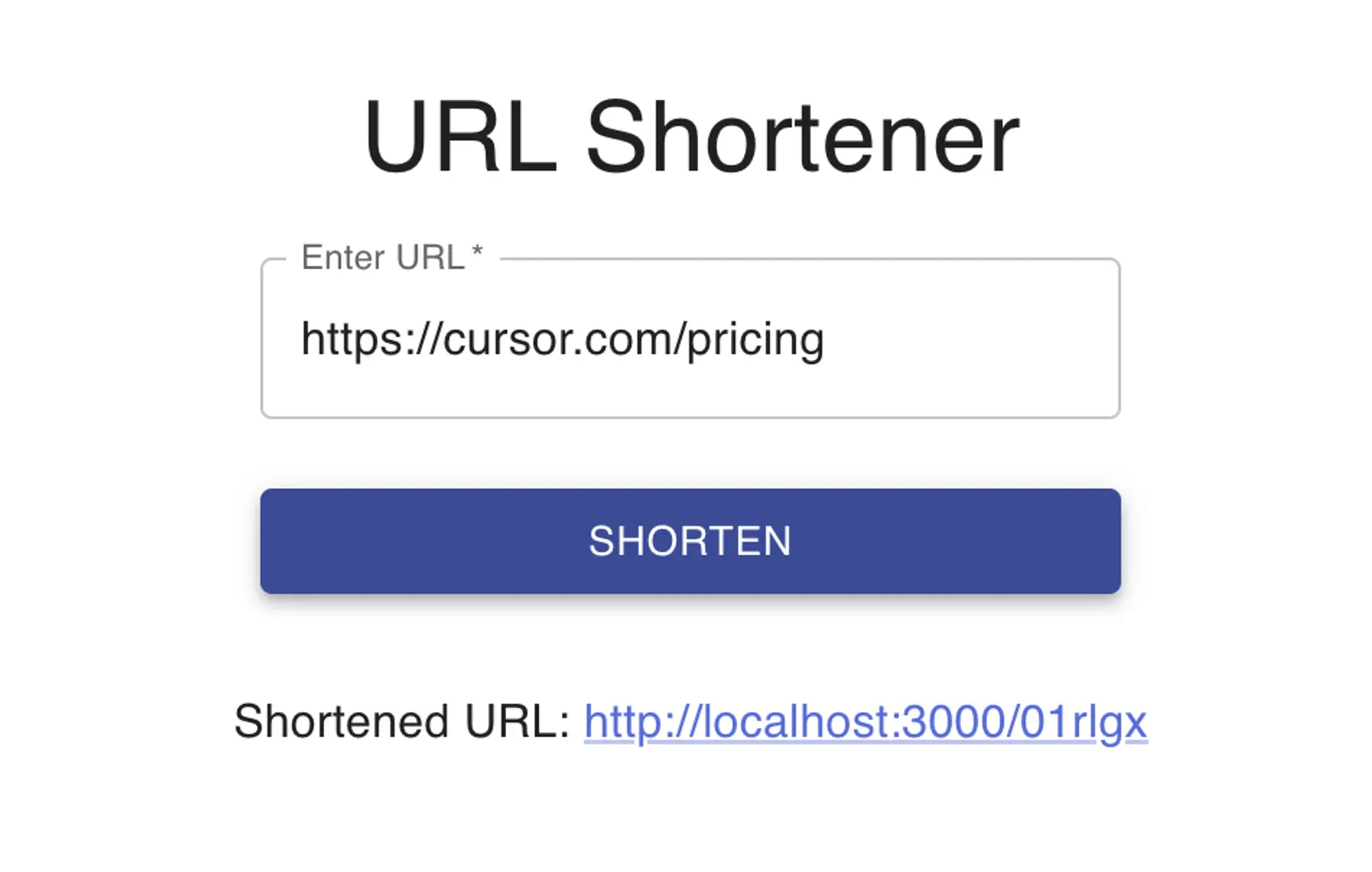
Poor Gemini had a lot of trouble with this test.
I felt that I had to guide Gemini through every step of the process; it struggled with a few basic Node.js errors before we even encountered the Next.js quirks that the other tools had trouble with. Once the app was finally built, it also had to resolve a few logic errors in the runtime.
The app itself was very barebones; I don’t think the agent even attempted to apply a custom style. What is worse is that it did not display any error or success messages, so when troubleshooting the functionality, I had to rely on the server logs to determine if it worked or not.
The boilerplate test was informative, but we’ve only scratched the surface of the usefulness of the tools for real work.
Test #2: Using AI agents on production code
For the real-world production tests, I just cycled through the tools as I went about my everyday code tasks on production systems.
There will, of course, be some variability in the tests because each tool was given a different task in each repo; however, I tried my best to give them an equal opportunity. The scoring on this section will be primarily based on my overall impression of the tool after working with it for some time.
Backend challenge: Kubernetes pod leader election (Go)
For the backend test, I needed to implement a pod leader election system to allow us to run only one cron job on a single replica of an app service. We’ll use the go-quartz library for cron scheduling, and we’ll need to convert existing data refresh functions to the new system once it’s in place. In addition to the task revolving around a relatively obscure library, we also had a custom logging implementation that would test the agent’s ability to analyze the codebase.
Claude Code
Claude came out of the gate strong with a good base implementation, but it had a hard time figuring out how to configure the go-quartz library.
What was impressive was that once it realized that it couldn’t figure out the problem, it automatically switched to a web Search tool and reached out to the GitHub page to read the documentation.
Cursor
With Cursor, we handled the next step of the feature: when running the service outside of Kubernetes, we need to ignore the pod leader logic and just schedule the crons.
The agent performed very well and completed the refactor on the first try with the proper context, keeping with our established patterns around Dependency Injection and factory functions, not returning structs, but interfaces, and other highly specific code style patterns that it could only know from reading the codebase as a whole.
I did have to follow up with a few minor clarifications, such as where it should get the Kubernetes namespace from, the docs for the K8s client show both a file and envar option, so Cursor just went with the most common implementation, but in our system, we happened to be using the opposite.
Gemini CLI
For Gemini’s task, I asked it to review the existing data refresh job and convert it to run within the cron scheduler.
Gemini is known for its massive context window, and it seems that the model is tuned to make the most of it. I worked in exactly the same way, and my prompts were functionally similar to the other tools, just describing the problem and providing a few relevant file paths; but it seems that Gemini was able to automatically load most, or at least all the relevant parts, of the codebase into the context window without my intervention.
Because of this behavior, it took some time to read all the files and build context. But once it was satisfied, it pulled off the refactor on the first try, with proper error handling and everything.
OpenAI Codex
Codex was given a different task in the same repo. Our service was having issues connecting to our NATS pub/sub server. I asked Codex to implement a connection retry failsafe, which we had not implemented elsewhere in the repository.
The model’s code accuracy was impressive, it was idiomatically correct and easy to read; I only provided one follow-up prompt to refine the code to match our standards and formatting rules. (which also highlights the fact that AI tools are still best utilized by experienced engineers who can audit the output).
Functionally, the code performed correctly on the first try, a testament to OpenAI’s model quality.
Frontend challenge: Astro blog templates (TypeScript)
For the frontend challenge, I would task the agents in creating a new page template for my website, which consists of an AstroJS base, with TailwindCSS and Keystatic CMS; nothing too crazy, but also not the most popular stack out there.
Claude Code
For this round, I decided to test Claude’s context gathering abilities with a refactor. The task was to convert some existing page templates from the built in Astro .md file data loaders to our new Keystatic data loader. To be successful, it would need to read the codebase for existing implementations, and implement a similar solution based on the shape of the data.
Unfortunately, it was not able to figure out the task on its own; it did see the other data loaders in the codebase, but the final product was an amalgamation of the two implementations.
With a bit more guidance, such as pointing the tool at very specific examples, I was finally able to get a working example out of it. This continues the pattern we’ve been seeing where more novel problems can confuse the tools due to there being a limited amount of past data.
Cursor
Cursor’s task consisted of creating a value calculator for a client site. I gave it detailed instructions on what the calculator fields should be and how it should work, then asked it to write React components in TypeScript, ensuring type safety and matching the existing CSS styles of the other components.
It did shockingly well! The component itself functioned perfectly on the first try, and only a few targeted prompts were needed to clean up the CSS styling to match the rest of the site.
Gemini CLI
With Gemini, I asked it to create an “About Us” page for my consulting website. The prompt included instructions on how the page should be laid out, as well as utilizing the Keystatic CMS data loader and existing Tailwind CSS classes.
The tool performed well, building a very functional about us page, which isn’t exactly a groundbreaking problem, but it did much better at figuring out the dataloader implementation than Claude; it also included an image carousel, which I hadn’t requested, but was so nicely designed that I ended up keeping it.
OpenAI Codex
For the front-end task, I wanted to stretch the o4 model a bit; I asked Codex to create a ‘roadmap’ component that maps out the consulting journey on my website.
The output was impressive, with a simple, but fully functional roadmap with icon items connected by line ‘paths’. The design matched the existing codebase styling, and the model even was aware enough to make the component hidden on mobile screen sizes, which I thought was exceptional reasoning!
It had very few issues that needed to be cleaned up; mainly around centering issues with the list of roadmap icons.
Final benchmarks for AI coding agents (2025)
With weeks’ worth of testing complete, I categorized our findings into seven categories:
Tool | Setup | Cost | Quality | Context | Integration | Speed | Specialized | Average |
|---|---|---|---|---|---|---|---|---|
Cursor | 9 | 5 | 9 | 8 | 8 | 9 | 8 | 8 |
Claude Code | 8 | 6 | 7 | 5 | 9 | 7 | 6 | 6.8 |
Gemini CLI | 6 | 8 | 7 | 9 | 5 | 5 | 8 | 6.8 |
OpenAI Codex | 3 | 6 | 8 | 7 | 4 | 7 | 7 | 6 |
I think the main takeaways here are that each tool excels in different areas, and that tools backed by really great models (looking at you, Codex) can be a pain to work with.
For vibe coding, I feel like prioritizing model quality and UX (for less experienced devs) will get you far; the best models can produce very good quality results on the first try, and average context window seems sufficient to keep the progress going. Vibe coding in general seems more and more impractical as codebases grow, so in my opinion hitting the context limit is further down the list of concerns.
For production work, refactoring, and the like, model quality is still important, but the more context on existing patterns you can pack in the better. For this purpose, Gemini and Cursor did the best and would be my first choice if I was outfitting an engineering team.
For myself, I was most impressed overall with Cursor. I thought it was just a VSCode re-skin utilizing other companies' models, but it's a great tool! Whatever they are doing under the hood to maximize model quality is really working!
Gemini surprised me with how well it handled the production tasks after falling short on boilerplate generation, making me wonder if it is tuned to make its decisions based on context rather than pre-training, which would make it better suited to editing an existing codebase, rather than generating a project from nothing. Documentation on this doesn’t exist, so we will just have to speculate.
For some reason, I was personally very drawn to Claude Code at first; it just felt the most productive and easy to use; the CLI output design was easy to read and the task planning and use approval flows just seemed to work. Even though Cursor outperformed Anthropic with their own model, I still feel like this is a great tool, and well worth trying out! After the full range of testing, the strain on its context window started to show, and it had trouble with more complex tasks.
Codex was, unfortunately, a great set of models with very serviceable context windows and output quality, but was held back by UX issues that didn’t inspire confidence. It is still worth trying out, as the quality of output was there; let's hope that OpenAI’s new venture, the cloud-based Codex tool, fixes some of these workflow issues and makes Codex a viable option.
My takeaways for using AI coding agents
At the end of this testing, I still maintain a healthy amount of skepticism for AI agents. They are great tools, but are best used in the hands of experienced engineers who can properly audit their output before committing any changes.
That being said, there are some obvious, immediate benefits that all teams can and should utilize right away.
- These tools are great at boilerplate generation, just watch for obvious issues and even old package versions. For example, some of the models in our test reverted to whatever version of Next.js was current at their last training; my ideal use case would be to utilize the official Next.js project generator and then use the agent to populate a basic implementation over the project base, thereby eliminating some of the common errors.
- With enough direction and context, they can be a helpful assistant on even complex production codebases, just make sure to audit every line of code. I do feel like the tools helped speed up my production workflow overall, using them primarily to stub out a new feature that I could meticulously review.
- A feature of Cursor that I didn’t talk about much, because it was the only tool to have it, is in-editor autocomplete, in which the agent was able to suggest the rest of the lines of code based on what I was doing; this in my opinion is an extraordinary force-multiplier in production, as it lets me keep tight control of what is being written, while still offering assistance.
- Another area where all of these agents were a great help was error research and resolution. When I ran into any error, whether it be a build or runtime error, or an obscure SQL error, instead of searching the web for it, I would first just plug it in to the chat window and it would more often or not, give a suggestion for a fix, or at the very least explain the issue. This sped up bug fixing substantially, to the point where even if an organization wasn’t ready to give AI agents code generation control, I would still recommend having one available as an “error assistant”.
- For deployment and DevOps work, they can be invaluable. The combination of Docker Compose for local debugging, along with the Render MCP for live deployment, meant that I didn’t have to touch a single line of infrastructure code or cloud console to get things up and running. In the long run, this could save a team a significant amount of time and money.
AI agents are here to stay, no matter what the code purists have to say, and I think it will provide a competitive advantage to those who learn how to use these tools, balanced out with good old-fashioned engineering principles.